
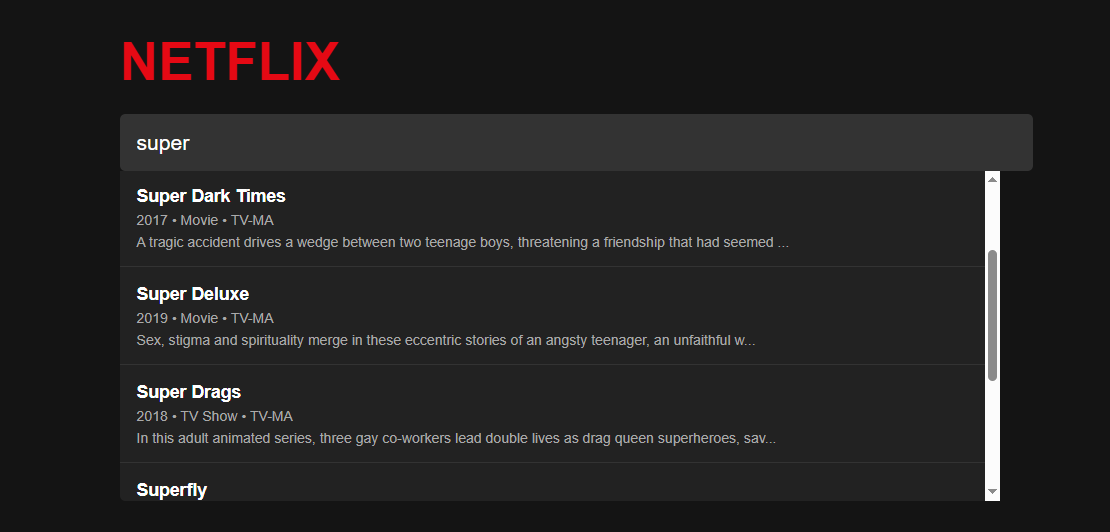
Netflix Autosuggest Search Engine
By Tejas Kamble – AI/ML Developer & Researcher | tejaskamble.com
Introduction
Have you ever used the Netflix search bar and instantly seen suggestions that seem to know exactly what you’re looking for—even before you finish typing? Inspired by this, I created a Netflix Search Engine using NLP Text Suggestions — a project that bridges the power of natural language processing (NLP) with real-time search functionalities.
In this post, I’ll walk you through the codebase hosted on my GitHub: Netflix_Search_Engine_NLP_Text_suggestion, breaking down each important part, from data loading and text preprocessing to building the suggestion logic and deploying it using Flask.
📂 Project Structure
Netflix_Search_Engine_NLP_Text_suggestion/
├── app.py ← Flask Web App
├── netflix_titles.csv ← Dataset of Netflix shows/movies
├── templates/
│ ├── index.html ← Frontend UI
├── static/
│ └── style.css ← Custom styling
├── requirements.txt ← Python dependencies
└── README.md ← Project overview
Dataset Overview
I used a dataset of Netflix titles (from Kaggle). It includes:
- Title: Name of the show/movie
- Description: Synopsis of the content
- Cast: Actors involved
- Genres, Date Added, Duration and more…
This dataset is essential for understanding user intent when making text suggestions.
Step-by-Step Breakdown of the Code
Loading the Dataset
df = pd.read_csv("netflix_titles.csv")
df.dropna(subset=['title'], inplace=True)
We load the dataset and ensure there are no missing values in the title column since that’s our search anchor.
Text Vectorization using TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words='english')
tfidf_matrix = vectorizer.fit_transform(df['title'])
- TF-IDF (Term Frequency-Inverse Document Frequency) is used to convert titles into numerical vectors.
- This helps quantify the importance of each word in the context of the entire dataset.
Cosine Similarity Search
from sklearn.metrics.pairwise import cosine_similarity
def get_recommendations(input_text):
input_vec = vectorizer.transform([input_text])
similarity = cosine_similarity(input_vec, tfidf_matrix)
indices = similarity.argsort()[0][-5:][::-1]
return df['title'].iloc[indices]
Here’s where the magic happens:
- The user input is vectorized.
- We compute cosine similarity with all titles.
- The top 5 most similar titles are returned as recommendations.
Flask Web Application
The search engine is hosted using a lightweight Flask backend.
@app.route("/", methods=["GET", "POST"])
def index():
if request.method == "POST":
user_input = request.form["title"]
suggestions = get_recommendations(user_input)
return render_template("index.html", suggestions=suggestions, query=user_input)
return render_template("index.html")
- Accepts user input from the HTML form
- Processes it through
get_recommendations() - Displays top matching titles
Frontend – index.html
A simple yet effective UI allows users to interact with the engine.
<form method="POST">
<input type="text" name="title" placeholder="Search for Netflix titles...">
<button type="submit">Search</button>
</form>
If suggestions are found, they’re shown dynamically below the form.
🌐 Deployment
To run this app locally:
git clone https://github.com/tejask0512/Netflix_Search_Engine_NLP_Text_suggestion
cd Netflix_Search_Engine_NLP_Text_suggestion
pip install -r requirements.txt
python app.py
Then open http://127.0.0.1:5000 in your browser!
Key Takeaways
- TF-IDF is powerful for information retrieval tasks.
- Even a simple cosine similarity search can replicate sophisticated autocomplete behavior.
- Flask makes it easy to bring machine learning to the web.
What’s Next?
Here are a few ways I plan to extend this project:
- Use BERT or Sentence Transformers for semantic similarity.
- Add spell correction and synonym support.
- Deploy it on Render, Heroku, or HuggingFace Spaces.
- Add a recommendation engine using genres, cast similarity, or collaborative filtering.
🧑💻 About Me
I’m Tejas Kamble, an AI/ML Developer & Researcher passionate about building intelligent, ethical, and multilingual human-computer interaction systems. I focus on:
- AI-driven trading strategies
- NLP-based behavioral analysis
- Real-time blockchain sentiment analysis
- Deep learning for crop disease detection
Check out more of my work on my GitHub @tejask0512
🌐 Website: tejaskamble.com
💬 Feedback & Collaboration
I’d love to hear your thoughts or collaborate on cool projects!
Let’s connect: tejaskamble.com/contact