
Machine learning projects can be structured in various ways, with general programming and modular programming being two common approaches. In this blog post, I’ll compare these methodologies and provide a comprehensive guide to building an ML project using a modular architecture.
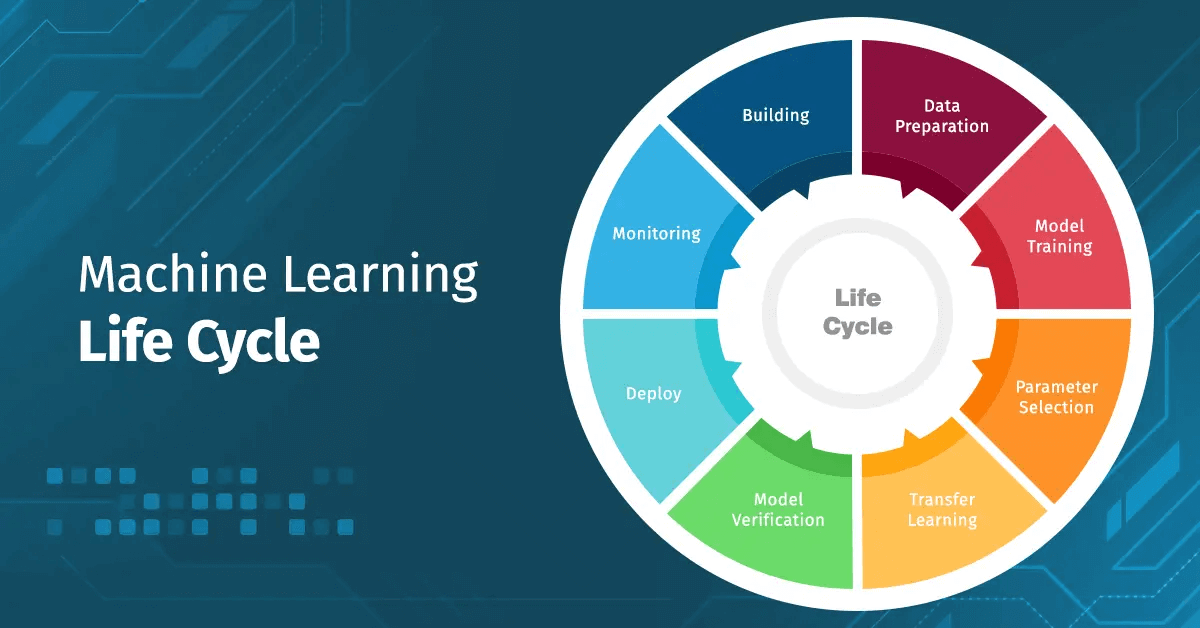
The Machine Learning Lifecycle
Before diving into programming approaches, let’s understand the typical machine learning project lifecycle:
- Data Ingestion: Collecting and importing data from various sources
- Data Validation: Ensuring data quality and integrity
- Data Transformation: Cleaning, preprocessing, and feature engineering
- Model Training: Building and training ML models on the prepared data
- Model Evaluation: Assessing model performance using relevant metrics
- Model Deployment: Deploying the model to production environments
- Monitoring: Tracking model performance and retraining as needed
General Programming vs. Modular Programming
General Programming Approach
In a general programming approach, the ML workflow is typically implemented in a few large script files. This approach has several characteristics:
- Simplicity: Easier to get started and understand the flow
- Quick Prototyping: Faster initial development for proof-of-concept
- Limited Scalability: Becomes difficult to maintain as project complexity grows
- Code Repetition: Often leads to duplicate code across different parts
- Testing Challenges: Difficult to test individual components separately
Modular Programming Approach
Modular programming breaks down the ML workflow into distinct, reusable components:
- Maintainability: Easier to maintain and update individual components
- Reusability: Components can be reused across different projects
- Testability: Components can be tested independently
- Collaboration: Multiple team members can work on different components
- Scalability: Better suited for complex, production-grade applications
ml_project/
├── .github/ # GitHub Actions workflows
├── config/ # Configuration files
│ └── config.yaml
├── logs/ # Log files
├── notebooks/ # Jupyter notebooks for exploration
├── src/ # Source code
│ ├── __init__.py
│ ├── components/ # Modular components
│ │ ├── __init__.py
│ │ ├── data_ingestion.py
│ │ ├── data_validation.py
│ │ ├── data_transformation.py
│ │ ├── model_trainer.py
│ │ ├── model_evaluation.py
│ │ └── model_deployment.py
│ ├── pipeline/ # Pipeline orchestration
│ │ ├── __init__.py
│ │ ├── training_pipeline.py
│ │ └── prediction_pipeline.py
│ ├── utils/ # Utility functions
│ │ ├── __init__.py
│ │ ├── common.py
│ │ └── logger.py
│ ├── exception/ # Custom exception handling
│ │ ├── __init__.py
│ │ └── exception_handler.py
│ └── entity/ # Data entities and schemas
│ ├── __init__.py
│ ├── config_entity.py
│ └── artifact_entity.py
├── artifacts/ # Generated artifacts during execution
├── tests/ # Unit and integration tests
│ ├── __init__.py
│ ├── unit/
│ └── integration/
├── README.md # Project documentation
├── requirements.txt # Package dependencies
├── setup.py # Package installation setup
└── main.py # Entry point for the applicationComponents of a Modular ML Project
Let’s explore the core components of our modular ML project:
1. Components Module
The components module contains individual classes for each step in the ML lifecycle:
Data Ingestion Component
Responsible for importing data from various sources and creating datasets.
# src/components/data_ingestion.py
import os
import sys
import pandas as pd
from dataclasses import dataclass
from sklearn.model_selection import train_test_split
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
@dataclass
class DataIngestionConfig:
"""Configuration for data ingestion."""
raw_data_path: str = os.path.join('artifacts', 'raw.csv')
train_data_path: str = os.path.join('artifacts', 'train.csv')
test_data_path: str = os.path.join('artifacts', 'test.csv')
class DataIngestion:
"""Class for data ingestion operations."""
def __init__(self, config: DataIngestionConfig = DataIngestionConfig()):
"""Initialize data ingestion with configuration."""
self.config = config
os.makedirs(os.path.dirname(config.raw_data_path), exist_ok=True)
def download_data(self, source_url: str) -> str:
"""
Download data from source URL.
Args:
source_url (str): URL to download data from
Returns:
str: Path where data is saved
"""
try:
logging.info("Initiating data download")
# Implementation for downloading data
# This could use requests, boto3, kaggle, etc. depending on source
logging.info("Data download completed")
return self.config.raw_data_path
except Exception as e:
logging.error("Error in data download")
raise CustomException(e, sys)
def split_data(self) -> tuple:
"""
Split data into training and testing sets.
Returns:
tuple: Paths to train and test data
"""
try:
logging.info("Splitting data into train and test sets")
df = pd.read_csv(self.config.raw_data_path)
train_set, test_set = train_test_split(
df, test_size=0.2, random_state=42
)
train_set.to_csv(self.config.train_data_path, index=False, header=True)
test_set.to_csv(self.config.test_data_path, index=False, header=True)
logging.info(f"Train data shape: {train_set.shape}")
logging.info(f"Test data shape: {test_set.shape}")
return (
self.config.train_data_path,
self.config.test_data_path
)
except Exception as e:
logging.error("Error in data splitting")
raise CustomException(e, sys)
def initiate_data_ingestion(self, source_url: str = None) -> tuple:
"""
Orchestrate the data ingestion process.
Args:
source_url (str, optional): URL to download data from
Returns:
tuple: Paths to train and test data
"""
try:
if source_url:
self.download_data(source_url)
return self.split_data()
except Exception as e:
raise CustomException(e, sys)Data Validation Component
Validates the quality and schema of the ingested data.
# src/components/data_validation.py
import os
import sys
import json
import pandas as pd
from dataclasses import dataclass
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
@dataclass
class DataValidationConfig:
"""Configuration for data validation."""
schema_file_path: str = os.path.join('config', 'schema.json')
validation_report_path: str = os.path.join('artifacts', 'validation_report.json')
class DataValidation:
"""Class for data validation operations."""
def __init__(self, config: DataValidationConfig = DataValidationConfig()):
"""Initialize data validation with configuration."""
self.config = config
def _read_schema(self) -> dict:
"""
Read schema configuration from JSON file.
Returns:
dict: Schema configuration
"""
try:
with open(self.config.schema_file_path, 'r') as f:
schema = json.load(f)
return schema
except Exception as e:
logging.error("Error reading schema file")
raise CustomException(e, sys)
def validate_columns(self, dataframe: pd.DataFrame, schema: dict) -> bool:
"""
Validate column names and types against schema.
Args:
dataframe (pd.DataFrame): DataFrame to validate
schema (dict): Schema configuration
Returns:
bool: True if validation passes
"""
try:
validation_status = True
# Validate column presence
all_columns = list(schema.keys())
for column in all_columns:
if column not in dataframe.columns:
validation_status = False
logging.error(f"Column {column} not found in the dataset")
# Validate column types (if needed)
# Add more validation as required
return validation_status
except Exception as e:
logging.error("Error validating columns")
raise CustomException(e, sys)
def validate_numerical_columns(self, dataframe: pd.DataFrame, schema: dict) -> bool:
"""
Validate numerical columns for null values and range checks.
Args:
dataframe (pd.DataFrame): DataFrame to validate
schema (dict): Schema configuration
Returns:
bool: True if validation passes
"""
try:
validation_status = True
for column, properties in schema.items():
if properties["type"] == "numerical":
# Check for null values
if dataframe[column].isnull().sum() > 0:
validation_status = False
logging.warning(f"Column {column} contains null values")
# Range check if specified
if "range" in properties:
min_val, max_val = properties["range"]
if dataframe[column].min() < min_val or dataframe[column].max() > max_val:
validation_status = False
logging.warning(f"Column {column} contains values outside expected range")
return validation_status
except Exception as e:
logging.error("Error validating numerical columns")
raise CustomException(e, sys)
def initiate_data_validation(self, train_path: str, test_path: str) -> bool:
"""
Orchestrate the data validation process.
Args:
train_path (str): Path to training data
test_path (str): Path to test data
Returns:
bool: Validation status
"""
try:
logging.info("Initiating data validation")
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
schema = self._read_schema()
# Validate columns in both datasets
train_validation = self.validate_columns(train_df, schema)
test_validation = self.validate_columns(test_df, schema)
# Validate numerical columns
train_num_validation = self.validate_numerical_columns(train_df, schema)
test_num_validation = self.validate_numerical_columns(test_df, schema)
validation_status = all([
train_validation,
test_validation,
train_num_validation,
test_num_validation
])
# Save validation report
report = {
"train_validation": train_validation,
"test_validation": test_validation,
"train_num_validation": train_num_validation,
"test_num_validation": test_num_validation,
"overall_status": validation_status
}
os.makedirs(os.path.dirname(self.config.validation_report_path), exist_ok=True)
with open(self.config.validation_report_path, 'w') as f:
json.dump(report, f, indent=4)
logging.info(f"Data validation completed with status: {validation_status}")
return validation_status
except Exception as e:
logging.error("Error in data validation")
raise CustomException(e, sys)Data Transformation Component
Handles data preprocessing, feature engineering, and transformation.
# src/components/data_transformation.py
import os
import sys
import numpy as np
import pandas as pd
from dataclasses import dataclass
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
from src.utils.common import save_object
@dataclass
class DataTransformationConfig:
"""Configuration for data transformation."""
preprocessor_path: str = os.path.join('artifacts', 'preprocessor.pkl')
transformed_train_path: str = os.path.join('artifacts', 'transformed_train.npz')
transformed_test_path: str = os.path.join('artifacts', 'transformed_test.npz')
class DataTransformation:
"""Class for data transformation operations."""
def __init__(self, config: DataTransformationConfig = DataTransformationConfig()):
"""Initialize data transformation with configuration."""
self.config = config
os.makedirs(os.path.dirname(config.preprocessor_path), exist_ok=True)
def get_data_transformer_object(self, numerical_features: list, categorical_features: list) -> ColumnTransformer:
"""
Create preprocessing pipelines for numerical and categorical features.
Args:
numerical_features (list): List of numerical feature names
categorical_features (list): List of categorical feature names
Returns:
ColumnTransformer: Scikit-learn preprocessor object
"""
try:
logging.info("Creating preprocessing object")
# Numerical pipeline
num_pipeline = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler())
]
)
# Categorical pipeline
cat_pipeline = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("one_hot_encoder", OneHotEncoder(handle_unknown='ignore')),
]
)
# Combine pipelines
preprocessor = ColumnTransformer(
[
("num_pipeline", num_pipeline, numerical_features),
("cat_pipeline", cat_pipeline, categorical_features)
]
)
logging.info("Preprocessing object created successfully")
return preprocessor
except Exception as e:
logging.error("Error in creating preprocessing object")
raise CustomException(e, sys)
def initiate_data_transformation(self, train_path: str, test_path: str, target_column: str = None) -> tuple:
"""
Orchestrate the data transformation process.
Args:
train_path (str): Path to training data
test_path (str): Path to test data
target_column (str, optional): Name of target column
Returns:
tuple: Paths to transformed datasets and preprocessor
"""
try:
logging.info("Initiating data transformation")
# Read train and test data
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
logging.info("Read train and test data completed")
# Separate features and target
if target_column:
input_feature_train_df = train_df.drop(columns=[target_column], axis=1)
target_feature_train_df = train_df[target_column]
input_feature_test_df = test_df.drop(columns=[target_column], axis=1)
target_feature_test_df = test_df[target_column]
else:
# If no target column, use all columns as features
input_feature_train_df = train_df
target_feature_train_df = None
input_feature_test_df = test_df
target_feature_test_df = None
# Identify numerical and categorical columns
numerical_columns = input_feature_train_df.select_dtypes(include=['int64', 'float64']).columns
categorical_columns = input_feature_train_df.select_dtypes(include=['object']).columns
# Create preprocessing object
preprocessor = self.get_data_transformer_object(
numerical_features=numerical_columns,
categorical_features=categorical_columns
)
# Transform data
input_feature_train_arr = preprocessor.fit_transform(input_feature_train_df)
input_feature_test_arr = preprocessor.transform(input_feature_test_df)
# Combine features and target
if target_column:
train_arr = np.c_[
input_feature_train_arr, np.array(target_feature_train_df)
]
test_arr = np.c_[
input_feature_test_arr, np.array(target_feature_test_df)
]
else:
train_arr = input_feature_train_arr
test_arr = input_feature_test_arr
# Save transformed data
np.savez(self.config.transformed_train_path, data=train_arr)
np.savez(self.config.transformed_test_path, data=test_arr)
# Save preprocessor
save_object(
file_path=self.config.preprocessor_path,
obj=preprocessor
)
logging.info("Data transformation completed")
return (
self.config.transformed_train_path,
self.config.transformed_test_path,
self.config.preprocessor_path
)
except Exception as e:
logging.error("Error in data transformation")
raise CustomException(e, sys)Model Trainer Component
Builds, trains, and tunes machine learning models.
src/components/model_trainer.py
import os
import sys
import numpy as np
from dataclasses import dataclass
from typing import Dict, List, Tuple
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.tree import DecisionTreeRegressor
from xgboost import XGBRegressor
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
from src.utils.common import save_object, load_object, evaluate_models
@dataclass
class ModelTrainerConfig:
“””Configuration for model trainer.”””
trained_model_path: str = os.path.join(‘artifacts’, ‘model.pkl’)
model_report_path: str = os.path.join(‘artifacts’, ‘model_report.json’)
class ModelTrainer:
“””Class for model training operations.”””
def __init__(self, config: ModelTrainerConfig = ModelTrainerConfig()):
"""Initialize model trainer with configuration."""
self.config = config
os.makedirs(os.path.dirname(config.trained_model_path), exist_ok=True)
def get_base_models(self) -> Dict:
"""
Create a dictionary of base models.
Returns:
Dict: Dictionary of model name and model object
"""
models = {
"Linear Regression": LinearRegression(),
"Ridge Regression": Ridge(),
"Lasso Regression": Lasso(),
"Decision Tree": DecisionTreeRegressor(),
"Random Forest": RandomForestRegressor(),
"Gradient Boosting": GradientBoostingRegressor(),
"XGBoost": XGBRegressor()
}
return models
def initiate_model_trainer(self,
train_array_path: str,
test_array_path: str,
target_column_index: int = -1) -> str:
"""
Orchestrate the model training process.
Args:
train_array_path (str): Path to transformed training data
test_array_path (str): Path to transformed test data
target_column_index (int, optional): Index of target column in arrays
Returns:
str: Path to best model
"""
try:
logging.info("Initiating model training")
# Load transformed data
train_data = np.load(train_array_path)['data']
test_data = np.load(test_array_path)['data']
# Split into features and target
X_train, y_train = train_data[:, :target_column_index], train_data[:, target_column_index]
X_test, y_test = test_data[:, :target_column_index], test_data[:, target_column_index]
logging.info(f"Loaded training and testing data")
logging.info(f"Training data shape: X={X_train.shape}, y={y_train.shape}")
logging.info(f"Testing data shape: X={X_test.shape}, y={y_test.shape}")
# Get base models
models = self.get_base_models()
# Set hyperparameters (if needed)
model_params = {
"Random Forest": {
'n_estimators': [100, 200],
'max_depth': [10, 15, 20],
'min_samples_split': [2, 5, 10]
},
"Gradient Boosting": {
'n_estimators': [100, 200],
'learning_rate': [0.01, 0.1]
},
"XGBoost": {
'n_estimators': [100, 200],
'learning_rate': [0.01, 0.1],
'max_depth': [3, 5, 7]
}
}
# Evaluate models
model_report = evaluate_models(
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
models=models,
param_grid=model_params
)
# Get best model score and name
best_score = max(sorted(model_report.values()))
best_model_name = list(model_report.keys())[
list(model_report.values()).index(best_score)
]
best_model = models[best_model_name]
if best_score < 0.6:
logging.warning("No model performed well. Best score is less than 0.6")
logging.info(f"Best model: {best_model_name} with score: {best_score}")
# Save best model
save_object(
file_path=self.config.trained_model_path,
obj=best_model
)
# Make predictions with best model
y_pred = best_model.predict(X_test)
# Calculate metrics
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
logging.info(f"Model metrics - R2: {r2}, MSE: {mse}, MAE: {mae}")
return self.config.trained_model_path
except Exception as e:
logging.error("Error in model training")
raise CustomException(e, sys)Model Evaluation Component
Evaluates model performance using various metrics.
# src/components/model_evaluation.py
import os
import sys
import json
import numpy as np
import pandas as pd
from dataclasses import dataclass
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
from src.utils.common import load_object
@dataclass
class ModelEvaluationConfig:
"""Configuration for model evaluation."""
evaluation_report_path: str = os.path.join('artifacts', 'evaluation_report.json')
class ModelEvaluation:
"""Class for model evaluation operations."""
def __init__(self, config: ModelEvaluationConfig = ModelEvaluationConfig()):
"""Initialize model evaluation with configuration."""
self.config = config
os.makedirs(os.path.dirname(config.evaluation_report_path), exist_ok=True)
def evaluate_regression_model(self,
y_true: np.ndarray,
y_pred: np.ndarray) -> dict:
"""
Evaluate regression model using various metrics.
Args:
y_true (np.ndarray): Actual values
y_pred (np.ndarray): Predicted values
Returns:
dict: Dictionary of evaluation metrics
"""
try:
metrics = {
"r2_score": float(r2_score(y_true, y_pred)),
"mean_squared_error": float(mean_squared_error(y_true, y_pred)),
"root_mean_squared_error": float(np.sqrt(mean_squared_error(y_true, y_pred))),
"mean_absolute_error": float(mean_absolute_error(y_true, y_pred))
}
return metrics
except Exception as e:
logging.error("Error in evaluating regression model")
raise CustomException(e, sys)
def initiate_model_evaluation(self,
test_array_path: str,
model_path: str,
preprocessor_path: str,
target_column_index: int = -1) -> dict:
"""
Orchestrate the model evaluation process.
Args:
test_array_path (str): Path to transformed test data
model_path (str): Path to trained model
preprocessor_path (str): Path to preprocessor object
target_column_index (int, optional): Index of target column in arrays
Returns:
dict: Evaluation report
"""
try:
logging.info("Initiating model evaluation")
# Load test data
test_data = np.load(test_array_path)['data']
X_test, y_test = test_data[:, :target_column_index], test_data[:, target_column_index]
# Load model and preprocessor
model = load_object(file_path=model_path)
preprocessor = load_object(file_path=preprocessor_path)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate model
metrics = self.evaluate_regression_model(y_test, y_pred)
# Create complete report
report = {
"model_path": model_path,
"preprocessor_path": preprocessor_path,
"test_data_shape": {
"X_test": X_test.shape,
"y_test": y_test.shape
},
"metrics": metrics
}
# Save report
with open(self.config.evaluation_report_path, 'w') as f:
json.dump(report, f, indent=4)
logging.info(f"Model evaluation completed: {metrics}")
return report
except Exception as e:
logging.error("Error in model evaluation")
raise CustomException(e, sys)
def compare_with_baseline(self,
test_array_path: str,
current_model_path: str,
baseline_model_path: str,
preprocessor_path: str,
target_column_index: int = -1) -> dict:
"""
Compare current model with baseline model.
Args:
test_array_path (str): Path to transformed test data
current_model_path (str): Path to current trained model
baseline_model_path (str): Path to baseline model
preprocessor_path (str): Path to preprocessor object
target_column_index (int, optional): Index of target column in arrays
Returns:
dict: Comparison report
"""
try:
logging.info("Comparing model with baseline")
# Load test data
test_data = np.load(test_array_path)['data']
X_test, y_test = test_data[:, :target_column_index], test_data[:, target_column_index]
# Load models
current_model = load_object(file_path=current_model_path)
baseline_model = load_object(file_path=baseline_model_path)
# Make predictions
current_pred = current_model.predict(X_test)
baseline_pred = baseline_model.predict(X_test)
# Evaluate models
current_metrics = self.evaluate_regression_model(y_test, current_pred)
baseline_metrics = self.evaluate_regression_model(y_test, baseline_pred)
# Create comparison report
report = {
"current_model": {
"path": current_model_path,
"metrics": current_metrics
},
"baseline_model": {
"path": baseline_model_path,
"metrics": baseline_metrics
},
"improvement": {
"r2_score": current_metrics["r2_score"] - baseline_metrics["r2_score"],
"mean_squared_error": baseline_metrics["mean_squared_error"] - current_metrics["mean_squared_error"],
"root_mean_squared_error": baseline_metrics["root_mean_squared_error"] - current_metrics["root_mean_squared_error"],
"mean_absolute_error": baseline_metrics["mean_absolute_error"] - current_metrics["mean_absolute_error"]
}
}
# Save report
comparison_report_path = os.path.join('artifacts', 'model_comparison_report.json')
with open(comparison_report_path, 'w') as f:
json.dump(report, f, indent=4)
logging.info(f"Model comparison completed")
return report
except Exception as e:
logging.error("Error in model comparison")
raise CustomException(e, sys)2. Pipeline Module
Orchestrates the execution of components in a sequential workflow:
src/pipeline/training_pipeline.py
import os
import sys
from src.components.data_ingestion import DataIngestion, DataIngestionConfig
from src.components.data_validation import DataValidation, DataValidationConfig
from src.components.data_transformation import DataTransformation, DataTransformationConfig
from src.components.model_trainer import ModelTrainer, ModelTrainerConfig
from src.components.model_evaluation import ModelEvaluation, ModelEvaluationConfig
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
class TrainingPipeline:
"""Class to orchestrate the training pipeline."""
def __init__(self):
"""Initialize the training pipeline."""
self.data_ingestion_config = DataIngestionConfig()
self.data_validation_config = DataValidationConfig()
self.data_transformation_config = DataTransformationConfig()
self.model_trainer_config = ModelTrainerConfig()
self.model_evaluation_config = ModelEvaluationConfig()
def start_data_ingestion(self, source_url: str = None):
"""
Start data ingestion component.
Args:
source_url (str, optional): URL to download data from
Returns:
tuple: Paths to train and test data
"""
try:
logging.info("Starting data ingestion")
data_ingestion = DataIngestion(self.data_ingestion_config)
train_data_path, test_data_path = data_ingestion.initiate_data_ingestion(source_url)
return train_data_path, test_data_path
except Exception as e:
logging.error("Error in data ingestion pipeline")
raise CustomException(e, sys)
def start_data_validation(self, train_data_path: str, test_data_path: str):
"""
Start data validation component.
Args:
train_data_path (str): Path to training data
test_data_path (str): Path to test data
Returns:
bool: Validation status
"""
try:
logging.info("Starting data validation")
data_validation = DataValidation(self.data_validation_config)
validation_status = data_validation.initiate_data_validation(train_data_path, test_data_path)
return validation_status
except Exception as e:
logging.error("Error in data validation pipeline")
raise CustomException(e, sys)
def start_data_transformation(self, train_data_path: str, test_data_path: str, target_column: str = None):
"""
Start data transformation component.
Args:
train_data_path (str): Path to training data
test_data_path (str): Path to test data
target_column (str, optional): Name of target column
Returns:
tuple: Paths to transformed data and preprocessor
"""
try:
logging.info("Starting data transformation")
data_transformation = DataTransformation(self.data_transformation_config)
transformed_train_path, transformed_test_path, preprocessor_path = data_transformation.initiate_data_transformation(
train_data_path, test_data_path, target_column
)
return transformed_train_path, transformed_test_path, preprocessor_path
except Exception as e:
logging.error("Error in data transformation pipeline")
raise CustomException(e, sys)
def start_model_training(self, transformed_train_path: str, transformed_test_path: str, target_column_index: int = -1):
"""
Start model trainer component.
Args:
transformed_train_path (str): Path to transformed training data
transformed_test_path (str): Path to transformed test data
target_column_index (int, optional): Index of target column
Returns:
str: Path to trained model
"""
try:
logging.info("Starting model training")
model_trainer = ModelTrainer(self.model_trainer_config)
model_path = model_trainer.initiate_model_trainer(
transformed_train_path, transformed_test_path, target_column_index
)
return model_path
except Exception as e:
logging.error("Error in model training pipeline")
raise CustomException(e, sys)
def start_model_evaluation(self, test_array_path: str, model_path: str, preprocessor_path: str, target_column_index: int = -1):
"""
Start model evaluation component.
Args:
test_array_path (str): Path to transformed test data
model_path (str): Path to trained model
preprocessor_path (str): Path to preprocessor
target_column_index (int, optional): Index of target column
Returns:
dict: Evaluation report
"""
try:
logging.info("Starting model evaluation")
model_evaluation = ModelEvaluation(self.model_evaluation_config)
evaluation_report = model_evaluation.initiate_model_evaluation(
test_array_path, model_path, preprocessor_path, target_column_index
)
return evaluation_report
except Exception as e:
logging.error("Error in model evaluation pipeline")
raise CustomException(e, sys)
def run_pipeline(self, source_url: str = None, target_column: str = None, target_column_index: int = -1):
"""
Run the complete training pipeline.
Args:
source_url (str, optional): URL to download data from
target_column (str, optional): Name of target column
target_column_index (int, optional): Index of target column
Returns:
dict: Pipeline results
"""
try:
logging.info("Starting training pipeline")
# Data Ingestion
train_data_path, test_data_path = self.start_data_ingestion(source_url)
# Data Validation
validation_status = self.start_data_validation(train_data_path, test_data_path)
if not validation_status:
logging.warning("Data validation failed, but continuing pipeline")
# Data Transformation
transformed_train_path, transformed_test_path, preprocessor_path = self.start_data_transformation(
train_data_path, test_data_path, target_column
)
# Model Training
model_path = self.start_model_training(
transformed_train_path, transformed_test_path, target_column_index
)
# Model Evaluation
evaluation_report = self.start_model_evaluation(
transformed_test_path, model_path, preprocessor_path, target_column_index
)
logging.info("Training pipeline completed successfully")
# Return pipeline results
return {
"train_data_path": train_data_path,
"test_data_path": test_data_path,
"transformed_train_path": transformed_train_path,
"transformed_test_path": transformed_test_path,
"preprocessor_path": preprocessor_path,
"model_path": model_path,
"evaluation_report": evaluation_report
}
except Exception as e:
logging.error("Error in training pipeline")
raise CustomException(e, sys)import os
import sys
import pandas as pd
import numpy as np
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
from src.utils.common import load_object
class PredictionPipeline:
"""Class to make predictions using trained model."""
def __init__(self, model_path: str = None, preprocessor_path: str = None):
"""
Initialize prediction pipeline.
Args:
model_path (str, optional): Path to trained model
preprocessor_path (str, optional): Path to preprocessor
"""
self.model_path = model_path or os.path.join('artifacts', 'model.pkl')
self.preprocessor_path = preprocessor_path or os.path.join('artifacts', 'preprocessor.pkl')
def predict(self, features: pd.DataFrame) -> np.ndarray:
"""
Make predictions on input features.
Args:
features (pd.DataFrame): Input features
Returns:
np.ndarray: Predictions
"""
try:
logging.info("Making predictions")
# Load model and preprocessor
preprocessor = load_object(file_path=self.preprocessor_path)
model = load_object(file_path=self.model_path)
# Transform features
transformed_features = preprocessor.transform(features)
# Make predictions
predictions = model.predict(transformed_features)
logging.info("Predictions made successfully")
return predictions
except Exception as e:
logging.error("Error making predictions")
raise CustomException(e, sys)
class CustomData:
"""Class to convert user input to DataFrame for prediction."""
def __init__(self, **kwargs):
"""
Initialize with feature values.
Args:
**kwargs: Feature name-value pairs
"""
self.feature_data = kwargs
def get_data_as_dataframe(self) -> pd.DataFrame:
"""
Convert feature data to DataFrame.
Returns:
pd.DataFrame: Features as DataFrame
"""
try:
return pd.DataFrame([self.feature_data])
except Exception as e:
logging.error("Error converting data to DataFrame")
raise CustomException(e, sys)3. Utility Module
The utility module provides common functions used across components:
# src/utils/common.py
import os
import sys
import pickle
import json
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import r2_score
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
def save_object(file_path: str, obj) -> None:
"""
Save object to disk using pickle.
Args:
file_path (str): Path to save the object
obj: Python object to save
"""
try:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
with open(file_path, "wb") as file_obj:
pickle.dump(obj, file_obj)
logging.info(f"Object saved to {file_path}")
except Exception as e:
logging.error(f"Error saving object: {e}")
raise CustomException(e, sys)
def load_object(file_path: str):
"""
Load object from disk using pickle.
Args:
file_path (str): Path to the saved object
Returns:
The loaded object
"""
try:
with open(file_path, "rb") as file_obj:
obj = pickle.load(file_obj)
logging.info(f"Object loaded from {file_path}")
return obj
except Exception as e:
logging.error(f"Error loading object: {e}")
raise CustomException(e, sys)
def evaluate_models(X_train, y_train, X_test, y_test, models, param_grid=None):
"""
Evaluate multiple models with optional hyperparameter tuning.
Args:
X_train: Training features
y_train: Training target
X_test: Test features
y_test: Test target
models (dict): Dictionary of models to evaluate
param_grid (dict, optional): Dictionary of hyperparameters for each model
Returns:
dict: Model names and their performance scores
"""
try:
report = {}
for model_name, model in models.items():
# Hyperparameter tuning if params provided
if param_grid and model_name in param_grid:
logging.info(f"Tuning hyperparameters for {model_name}")
grid_search = GridSearchCV(
model,
param_grid[model_name],
cv=3,
scoring='r2',
n_jobs=-1
)
grid_search.fit(X_train, y_train)
# Get best model
model = grid_search.best_estimator_
models[model_name] = model # Update model with best params
logging.info(f"Best parameters for {model_name}: {grid_search.best_params_}")
else:
# Train model with default parameters
model.fit(X_train, y_train)
# Make predictions
y_test_pred = model.predict(X_test)
# Evaluate model
test_score = r2_score(y_test, y_test_pred)
# Store score
report[model_name] = test_score
logging.info(f"{model_name} - Test R2 Score: {test_score}")
return report
except Exception as e:
logging.error(f"Error evaluating models: {e}")
raise CustomException(e, sys)
def load_json(file_path: str) -> dict:
"""
Load JSON file.
Args:
file_path (str): Path to JSON file
Returns:
dict: Loaded JSON data
"""
try:
with open(file_path, 'r') as f:
data = json.load(f)
return data
except Exception as e:
logging.error(f"Error loading JSON file: {e}")
raise CustomException(e, sys)
def save_json(file_path: str, data: dict) -> None:
"""
Save data to JSON file.
Args:
file_path (str): Path to save JSON file
data (dict): Data to save
"""
try:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
with open(file_path, 'w') as f:
json.dump(data, f, indent=4)
logging.info(f"JSON saved to {file_path}")
except Exception as e:
logging.error(f"Error saving JSON file: {e}")
raise CustomException(e, sys)# src/utils/logger.py
import logging
import os
from datetime import datetime
# Create logs directory
LOG_DIR = "logs"
os.makedirs(LOG_DIR, exist_ok=True)
# Create log file with timestamp
LOG_FILE = f"{datetime.now().strftime('%Y-%m-%d_%H-%M-%S')}.log"
LOG_FILE_PATH = os.path.join(LOG_DIR, LOG_FILE)
# Configure logging
logging.basicConfig(
filename=LOG_FILE_PATH,
format="[ %(asctime)s ] %(lineno)d %(name)s - %(levelname)s - %(message)s",
level=logging.INFO,
)
# Add console handler for logging to console as well
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
formatter = logging.Formatter("[ %(asctime)s ] %(lineno)d %(name)s - %(levelname)s - %(message)s")
console_handler.setFormatter(formatter)
logging.getLogger().addHandler(console_handler)4. Exception Module
For custom exception handling:
src/exception/exception_handler.py
import sys
from src.utils.logger import logging
def error_message_detail(error, error_detail: sys):
“””
Create detailed error message with file and line information.
Args:
error: The error/exception object
error_detail: Error details from sys.exc_info()
Returns:
str: Formatted error message
"""
_, _, exc_tb = error_detail.exc_info()
file_name = exc_tb.tb_frame.f_code.co_filename
line_number = exc_tb.tb_lineno
error_message = f"Error occurred in Python script name [{file_name}] line number [{line_number}] error message [{str(error)}]"
return error_messageclass CustomException(Exception):
“””Custom exception class with detailed error message.”””
def __init__(self, error_message, error_detail: sys):
"""
Initialize custom exception.
Args:
error_message: Error message or exception
error_detail: Error details, typically sys module
"""
super().__init__(error_message)
self.error_message = error_message_detail(
error_message, error_detail=error_detail
)
def __str__(self):
"""
String representation of the exception.
Returns:
str: Error message
"""
return self.error_message5. Entity Module
For defining data structures and configurations:
# src/entity/config_entity.py
from dataclasses import dataclass
import os
@dataclass
class DataIngestionConfig:
"""Configuration for data ingestion."""
raw_data_path: str = os.path.join('artifacts', 'raw.csv')
train_data_path: str = os.path.join('artifacts', 'train.csv')
test_data_path: str = os.path.join('artifacts', 'test.csv')
@dataclass
class DataValidationConfig:
"""Configuration for data validation."""
schema_file_path: str = os.path.join('config', 'schema.json')
validation_report_path: str = os.path.join('artifacts', 'validation_report.json')
@dataclass
class DataTransformationConfig:
"""Configuration for data transformation."""
preprocessor_path: str = os.path.join('artifacts', 'preprocessor.pkl')
transformed_train_path: str = os.path.join('artifacts', 'transformed_train.npz')
transformed_test_path: str = os.path.join('artifacts', 'transformed_test.npz')
@dataclass
class ModelTrainerConfig:
"""Configuration for model trainer."""
trained_model_path: str = os.path.join('artifacts', 'model.pkl')
model_report_path: str = os.path.join('artifacts', 'model_report.json')
@dataclass
class ModelEvaluationConfig:
"""Configuration for model evaluation."""
evaluation_report_path: str = os.path.join('artifacts', 'evaluation_report.json')
@dataclass
class ModelDeploymentConfig:
"""Configuration for model deployment."""
model_deployment_path: str = os.path.join('artifacts', 'deployment')
# Add more deployment-specific configurations if neededArtifact Entity
# src/entity/artifact_entity.py
from dataclasses import dataclass
@dataclass
class DataIngestionArtifact:
"""Artifact produced by data ingestion component."""
train_file_path: str
test_file_path: str
@dataclass
class DataValidationArtifact:
"""Artifact produced by data validation component."""
validation_status: bool
validation_report_path: str
schema_file_path: str
@dataclass
class DataTransformationArtifact:
"""Artifact produced by data transformation component."""
transformed_train_path: str
transformed_test_path: str
preprocessor_path: str
@dataclass
class ModelTrainerArtifact:
"""Artifact produced by model trainer component."""
model_path: str
model_score: float
@dataclass
class ModelEvaluationArtifact:
"""Artifact produced by model evaluation component."""
is_model_accepted: bool
evaluation_report_path: str
@dataclass
class ModelDeploymentArtifact:
"""Artifact produced by model deployment component."""
deployment_status: bool
deployed_model_path: str
# Add more deployment artifacts if neededSetting Up the Project
Now let’s create the essential files for package setup and installation.
setup.py
This file is crucial for making your module installable and distributable:
from setuptools import find_packages, setup
from typing import List
# Declaring variables for setup functions
PROJECT_NAME = "ml-modular-project"
VERSION = "0.0.1"
AUTHOR = "Your Name"
DESCRIPTION = "A modular machine learning project"
REQUIREMENT_FILE_NAME = "requirements.txt"
def get_requirements_list() -> List[str]:
"""
This function returns a list of requirements from the requirements.txt file.
Returns:
List[str]: List of required packages
"""
with open(REQUIREMENT_FILE_NAME) as requirement_file:
return requirement_file.readlines().remove("-e .")
setup(
name=PROJECT_NAME,
version=VERSION,
author=AUTHOR,
description=DESCRIPTION,
packages=find_packages(),
install_requires=get_requirements_list()
)requirements.txt
List of all dependencies needed for the project:
pandas==2.0.3
numpy==1.24.3
scikit-learn==1.3.0
xgboost==1.7.6
matplotlib==3.7.2
seaborn==0.12.2
dill==0.3.7
fastapi==0.104.0
uvicorn==0.23.2
python-multipart==0.0.6
PyYAML==6.0.1
pytest==7.4.0
-e .main.py
The entry point for your application:
# main.py
import sys
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
from src.pipeline.training_pipeline import TrainingPipeline
from src.pipeline.prediction_pipeline import PredictionPipeline, CustomData
def start_training():
"""Start the training pipeline."""
try:
logging.info("Starting training process")
# Initialize training pipeline
pipeline = TrainingPipeline()
# Example configurations
source_url = None # Optional URL to download data from
target_column = "target" # Target column name
target_column_index = -1 # Target column index in the numpy array
# Run the pipeline
results = pipeline.run_pipeline(
source_url=source_url,
target_column=target_column,
target_column_index=target_column_index
)
logging.info(f"Training completed with results: {results}")
return results
except Exception as e:
logging.error("Error in training")
raise CustomException(e, sys)
def start_prediction(data, model_path=None, preprocessor_path=None):
"""
Make predictions on input data.
Args:
data (dict): Input feature values
model_path (str, optional): Path to model
preprocessor_path (str, optional): Path to preprocessor
Returns:
Any: Prediction result
"""
try:
logging.info("Starting prediction process")
# Convert input data to DataFrame
custom_data = CustomData(**data)
features_df = custom_data.get_data_as_dataframe()
# Initialize prediction pipeline
prediction_pipeline = PredictionPipeline(
model_path=model_path,
preprocessor_path=preprocessor_path
)
# Make prediction
predictions = prediction_pipeline.predict(features_df)
logging.info(f"Prediction completed: {predictions}")
return predictions[0]
except Exception as e:
logging.error("Error in prediction")
raise CustomException(e, sys)
if __name__ == "__main__":
# Example: Run training
training_results = start_training()
# Example: Make prediction
sample_data = {
"feature1": 10,
"feature2": 20,
"feature3": "category_a"
}
prediction = start_prediction(
data=sample_data,
model_path=training_results["model_path"],
preprocessor_path=training_results["preprocessor_path"]
)
print(f"Prediction result: {prediction}")Automatic Setup
To automate the setup of components, we can create a script that generates the project structure:
# project_setup.py
import os
import sys
import shutil
def create_directory_structure():
"""Create the project directory structure."""
directories = [
"artifacts",
"config",
"logs",
"notebooks",
"src",
"src/components",
"src/pipeline",
"src/utils",
"src/exception",
"src/entity",
"tests",
"tests/unit",
"tests/integration"
]
for directory in directories:
os.makedirs(directory, exist_ok=True)
# Create __init__.py in Python module directories
if "src" in directory or "tests" in directory:
with open(os.path.join(directory, "__init__.py"), 'w') as f:
pass
print("Directory structure created successfully.")
def create_config_files():
"""Create configuration files."""
# Create schema.json
schema_json = {
"feature1": {"type": "numerical", "range": [0, 100]},
"feature2": {"type": "numerical", "range": [0, 500]},
"feature3": {"type": "categorical", "categories": ["category_a", "category_b", "category_c"]}
}
import json
with open(os.path.join("config", "schema.json"), 'w') as f:
json.dump(schema_json, f, indent=4)
# Create config.yaml
config_yaml = """
data_ingestion:
source_url: null
raw_data_path: artifacts/raw.csv
train_data_path: artifacts/train.csv
test_data_path: artifacts/test.csv
data_validation:
schema_file_path: config/schema.json
validation_report_path: artifacts/validation_report.json
data_transformation:
preprocessor_path: artifacts/preprocessor.pkl
transformed_train_path: artifacts/transformed_train.npz
transformed_test_path: artifacts/transformed_test.npz
model_trainer:
trained_model_path: artifacts/model.pkl
model_report_path: artifacts/model_report.json
model_evaluation:
evaluation_report_path: artifacts/evaluation_report.json
"""
with open(os.path.join("config", "config.yaml"), 'w') as f:
f.write(config_yaml)
print("Configuration files created successfully.")
def create_template_files():
"""Create template files for components."""
components = [
"data_ingestion",
"data_validation",
"data_transformation",
"model_trainer",
"model_evaluation",
"model_deployment"
]
# Template content
template = """# src/components/{component}.py
import os
import sys
from dataclasses import dataclass
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
@dataclass
class {class_name}Config:
\"\"\"Configuration for {component_title}.\"\"\"
# Add configuration parameters here
pass
class {class_name}:
\"\"\"Class for {component_title} operations.\"\"\"
def __init__(self, config: {class_name}Config = {class_name}Config()):
\"\"\"Initialize {component_title} with configuration.\"\"\"
self.config = config
def initiate_{component}(self):
\"\"\"
Orchestrate the {component_title} process.
Returns:
Any: Result of {component_title}
\"\"\"
try:
logging.info("Initiating {component_title}")
# Implementation here
logging.info("{component_title} completed")
return "Success"
except Exception as e:
logging.error("Error in {component_title}")
raise CustomException(e, sys)
"""
for component in components:
class_name = "".join(word.capitalize() for word in component.split("_"))
component_title = " ".join(word for word in component.split("_"))
file_content = template.format(
component=component,
class_name=class_name,
component_title=component_title
)
with open(os.path.join("src", "components", f"{component}.py"), 'w') as f:
f.write(file_content)
# Create pipeline templates
pipeline_template = """# src/pipeline/{pipeline}.py
import os
import sys
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
class {class_name}:
\"\"\"Class to orchestrate the {pipeline_title} pipeline.\"\"\"
def __init__(self):
\"\"\"Initialize the {pipeline_title} pipeline.\"\"\"
pass
def run_pipeline(self):
\"\"\"
Run the complete {pipeline_title} pipeline.
Returns:
dict: Pipeline results
\"\"\"
try:
logging.info("Starting {pipeline_title} pipeline")
# Implementation here
logging.info("{pipeline_title} pipeline completed successfully")
return {"status": "success"}
except Exception as e:
logging.error("Error in {pipeline_title} pipeline")
raise CustomException(e, sys)
"""
pipelines = [
"training_pipeline",
"prediction_pipeline"
]
for pipeline in pipelines:
class_name = "".join(word.capitalize() for word in pipeline.split("_"))
pipeline_title = " ".join(word for word in pipeline.split("_"))
file_content = pipeline_template.format(
pipeline=pipeline,
class_name=class_name,
pipeline_title=pipeline_title
)
with open(os.path.join("src", "pipeline", f"{pipeline}.py"), 'w') as f:
f.write(file_content)
# project_setup.py (continued)
# Create utility templates
utils = ["common", "logger"]
utils_template = """# src/utils/{util}.py
import os
import sys
from src.exception.exception_handler import CustomException
def sample_function():
\"\"\"Sample utility function.\"\"\"
try:
return "Success"
except Exception as e:
raise CustomException(e, sys)
"""
for util in utils:
with open(os.path.join("src", "utils", f"{util}.py"), 'w') as f:
f.write(utils_template.format(util=util))
# Create exception handler template
exception_template = """# src/exception/exception_handler.py
import sys
def error_message_detail(error, error_detail: sys):
\"\"\"
Create detailed error message with file and line information.
Args:
error: The error/exception object
error_detail: Error details from sys.exc_info()
Returns:
str: Formatted error message
\"\"\"
_, _, exc_tb = error_detail.exc_info()
file_name = exc_tb.tb_frame.f_code.co_filename
line_number = exc_tb.tb_lineno
error_message = f"Error occurred in Python script name [{file_name}] line number [{line_number}] error message [{str(error)}]"
return error_message
class CustomException(Exception):
\"\"\"Custom exception class with detailed error message.\"\"\"
def __init__(self, error_message, error_detail: sys):
\"\"\"
Initialize custom exception.
Args:
error_message: Error message or exception
error_detail: Error details, typically sys module
\"\"\"
super().__init__(error_message)
self.error_message = error_message_detail(
error_message, error_detail=error_detail
)
def __str__(self):
\"\"\"
String representation of the exception.
Returns:
str: Error message
\"\"\"
return self.error_message
"""
with open(os.path.join("src", "exception", "exception_handler.py"), 'w') as f:
f.write(exception_template)
# Create entity template files
entity_files = ["config_entity", "artifact_entity"]
entity_template = """# src/entity/{entity}.py
from dataclasses import dataclass
@dataclass
class SampleConfig:
\"\"\"Sample configuration class.\"\"\"
param1: str = "default_value"
param2: int = 10
"""
for entity in entity_files:
with open(os.path.join("src", "entity", f"{entity}.py"), 'w') as f:
f.write(entity_template.format(entity=entity))
print("Template files created successfully.")
def create_main_file():
"""Create main.py file."""
main_template = """# main.py
import sys
from src.exception.exception_handler import CustomException
from src.utils.logger import logging
from src.pipeline.training_pipeline import TrainingPipeline
from src.pipeline.prediction_pipeline import PredictionPipeline
def start_training():
\"\"\"Start the training pipeline.\"\"\"
try:
logging.info("Starting training process")
# Initialize training pipeline
pipeline = TrainingPipeline()
# Run the pipeline
results = pipeline.run_pipeline()
logging.info(f"Training completed with results: {results}")
return results
except Exception as e:
logging.error("Error in training")
raise CustomException(e, sys)
def start_prediction(data):
\"\"\"
Make predictions on input data.
Args:
data (dict): Input feature values
Returns:
Any: Prediction result
\"\"\"
try:
logging.info("Starting prediction process")
# Initialize prediction pipeline
prediction_pipeline = PredictionPipeline()
# Make prediction
predictions = prediction_pipeline.run_pipeline(data)
logging.info(f"Prediction completed: {predictions}")
return predictions
except Exception as e:
logging.error("Error in prediction")
raise CustomException(e, sys)
if __name__ == "__main__":
# Example: Run training
training_results = start_training()
# Example: Make prediction
sample_data = {
"feature1": 10,
"feature2": 20,
"feature3": "category_a"
}
prediction = start_prediction(sample_data)
print(f"Prediction result: {prediction}")
"""
with open("main.py", 'w') as f:
f.write(main_template)
print("Main file created successfully.")
def create_setup_files():
"""Create setup files for the package."""
setup_py = """from setuptools import find_packages, setup
from typing import List
# Declaring variables for setup functions
PROJECT_NAME = "ml-modular-project"
VERSION = "0.0.1"
AUTHOR = "Your Name"
DESCRIPTION = "A modular machine learning project"
REQUIREMENT_FILE_NAME = "requirements.txt"
def get_requirements_list() -> List[str]:
\"\"\"
This function returns a list of requirements from the requirements.txt file.
Returns:
List[str]: List of required packages
\"\"\"
with open(REQUIREMENT_FILE_NAME) as requirement_file:
requirements = requirement_file.readlines()
if "-e ." in requirements:
requirements.remove("-e .")
return [req.strip() for req in requirements]
setup(
name=PROJECT_NAME,
version=VERSION,
author=AUTHOR,
description=DESCRIPTION,
packages=find_packages(),
install_requires=get_requirements_list()
)
"""
with open("setup.py", 'w') as f:
f.write(setup_py)
requirements_txt = """pandas>=1.3.0
numpy>=1.20.0
scikit-learn>=1.0.0
xgboost>=1.5.0
matplotlib>=3.4.0
seaborn>=0.11.0
dill>=0.3.0
fastapi>=0.70.0
uvicorn>=0.15.0
python-multipart>=0.0.5
PyYAML>=6.0
pytest>=6.2.5
-e .
"""
with open("requirements.txt", 'w') as f:
f.write(requirements_txt)
# Create README.md
readme_md = """# Modular Machine Learning Project
A template for creating modular machine learning projects with best practices.
## Project Structure
```
ml-modular-project/
├── artifacts/ # Stores generated artifacts during pipeline execution
├── config/ # Configuration files
├── logs/ # Log files
├── notebooks/ # Jupyter notebooks for exploration
├── src/ # Source code
│ ├── components/ # Pipeline components
│ ├── entity/ # Data structures and configuration entities
│ ├── exception/ # Custom exception handling
│ ├── pipeline/ # Pipeline orchestration
│ └── utils/ # Utility functions
├── tests/ # Test cases
├── main.py # Entry point
├── requirements.txt # Project dependencies
└── setup.py # Package setup file
```
## Installation
```bash
pip install -r requirements.txt
```
## Usage
### Training
```python
from main import start_training
results = start_training()
```
### Prediction
```python
from main import start_prediction
data = {
"feature1": 10,
"feature2": 20,
"feature3": "category_a"
}
prediction = start_prediction(data)
```
"""
with open("README.md", 'w') as f:
f.write(readme_md)
print("Setup files created successfully.")
def create_test_files():
"""Create template test files."""
unit_test_template = """# tests/unit/test_{component}.py
import unittest
import os
import sys
import shutil
from src.components.{component} import {class_name}
class Test{class_name}(unittest.TestCase):
\"\"\"Unit tests for {class_name} component.\"\"\"
def setUp(self):
\"\"\"Set up test environment.\"\"\"
# Setup code here
pass
def tearDown(self):
\"\"\"Clean up test environment.\"\"\"
# Cleanup code here
pass
def test_initiate_{component}(self):
\"\"\"Test initiate_{component} method.\"\"\"
# Test implementation here
self.assertTrue(True)
if __name__ == "__main__":
unittest.main()
"""
components = [
"data_ingestion",
"data_validation",
"data_transformation",
"model_trainer",
"model_evaluation"
]
for component in components:
class_name = "".join(word.capitalize() for word in component.split("_"))
with open(os.path.join("tests", "unit", f"test_{component}.py"), 'w') as f:
f.write(unit_test_template.format(component=component, class_name=class_name))
# Create integration test template
integration_test_template = """# tests/integration/test_pipeline.py
import unittest
import os
import sys
import shutil
from src.pipeline.training_pipeline import TrainingPipeline
from src.pipeline.prediction_pipeline import PredictionPipeline
class TestPipelines(unittest.TestCase):
\"\"\"Integration tests for pipelines.\"\"\"
def setUp(self):
\"\"\"Set up test environment.\"\"\"
# Setup code here
pass
def tearDown(self):
\"\"\"Clean up test environment.\"\"\"
# Cleanup code here
pass
def test_training_pipeline(self):
\"\"\"Test training pipeline.\"\"\"
# Test implementation here
self.assertTrue(True)
def test_prediction_pipeline(self):
\"\"\"Test prediction pipeline.\"\"\"
# Test implementation here
self.assertTrue(True)
if __name__ == "__main__":
unittest.main()
"""
with open(os.path.join("tests", "integration", "test_pipeline.py"), 'w') as f:
f.write(integration_test_template)
print("Test files created successfully.")
def main():
"""Main function to orchestrate project setup."""
try:
print("Starting project setup...")
create_directory_structure()
create_config_files()
create_template_files()
create_main_file()
create_setup_files()
create_test_files()
print("\nProject setup completed successfully!")
print("\nTo get started:")
print("1. Install requirements: pip install -r requirements.txt")
print("2. Run the project: python main.py")
except Exception as e:
print(f"Error in project setup: {e}")
sys.exit(1)
if __name__ == "__main__":
main()Building Production-Ready ML Projects: A Modular Approach
Building Production-Ready ML Projects: A Modular Approach
In the fast-evolving landscape of machine learning applications, developing production-ready projects demands more than just model building. It requires a systematic approach with proper organization, error handling, logging, and a modular architecture. This blog post introduces a comprehensive framework for creating modular machine learning projects that are robust, maintainable, and ready for production deployment.
Why Modular Architecture Matters in ML Projects
Machine learning projects often begin as exploratory notebooks but rapidly grow complex when transitioning to production. A modular architecture addresses several challenges:
- Maintainability: Isolating components makes code easier to maintain and update
- Reusability: Well-defined modules can be reused across different projects
- Testability: Independent components are easier to test thoroughly
- Collaboration: Clear boundaries enable teams to work on different components simultaneously
- Deployment: Modular systems are easier to deploy and scale in production environments
Project Structure
Our modular ML project template follows this structure:
ml-modular-project/
├── artifacts/ # Stores generated artifacts during pipeline execution
├── config/ # Configuration files
├── logs/ # Log files
├── notebooks/ # Jupyter notebooks for exploration
├── src/ # Source code
│ ├── components/ # Pipeline components
│ ├── entity/ # Data structures and configuration entities
│ ├── exception/ # Custom exception handling
│ ├── pipeline/ # Pipeline orchestration
│ └── utils/ # Utility functions
├── tests/ # Test cases
├── main.py # Entry point
├── requirements.txt # Project dependencies
└── setup.py # Package setup file
Core Components
1. Data Ingestion
The data ingestion component handles importing data from various sources (databases, CSV files, APIs) and splitting it into training and testing datasets. Its key responsibilities include:
- Downloading data from specified sources
- Reading data into appropriate formats
- Performing initial cleaning if necessary
- Splitting data into training and testing sets
- Saving processed datasets
2. Data Validation
Data validation ensures that incoming data meets expected quality standards before proceeding to model training. This component:
- Validates schema conformance (column names, data types)
- Checks for missing values and outliers
- Verifies data distributions
- Generates validation reports
- Raises alerts when data quality issues arise
3. Data Transformation
The transformation component prepares data for machine learning algorithms by:
- Handling missing values
- Encoding categorical variables
- Scaling numerical features
- Creating feature pipelines
- Generating new features
- Saving transformation artifacts for prediction
4. Model Trainer
This component handles the machine learning model development:
- Training different model algorithms
- Tuning hyperparameters
- Evaluating model performance
- Saving trained models
- Generating training reports
5. Model Evaluation
The evaluation component assesses model performance against production or baseline models:
- Comparing metrics with existing models
- Determining if a new model is better than the current one
- Creating detailed evaluation reports
- Deciding whether to accept or reject new models
Pipeline Orchestration
Two main pipelines orchestrate the flow of data and operations:
Training Pipeline
The training pipeline coordinates the end-to-end model development process:
class TrainingPipeline:
def run_pipeline(self, source_url=None, target_column=None, target_column_index=-1):
# Data Ingestion
train_data_path, test_data_path = self.start_data_ingestion(source_url)
# Data Validation
validation_status = self.start_data_validation(train_data_path, test_data_path)
# Data Transformation
transformed_train_path, transformed_test_path, preprocessor_path = self.start_data_transformation(
train_data_path, test_data_path, target_column
)
# Model Training
model_path = self.start_model_training(
transformed_train_path, transformed_test_path, target_column_index
)
# Model Evaluation
evaluation_report = self.start_model_evaluation(
transformed_test_path, model_path, preprocessor_path, target_column_index
)
return {
"model_path": model_path,
"preprocessor_path": preprocessor_path,
"evaluation_report": evaluation_report
}
Prediction Pipeline
The prediction pipeline handles making predictions using trained models:
class PredictionPipeline:
def predict(self, features: pd.DataFrame) -> np.ndarray:
# Load model and preprocessor
preprocessor = load_object(file_path=self.preprocessor_path)
model = load_object(file_path=self.model_path)
# Transform features
transformed_features = preprocessor.transform(features)
# Make predictions
predictions = model.predict(transformed_features)
return predictions
Utilities and Support Features
Custom Exception Handling
A robust error handling system improves debugging and troubleshooting:
class CustomException(Exception):
def __init__(self, error_message, error_detail: sys):
super().__init__(error_message)
self.error_message = error_message_detail(
error_message, error_detail=error_detail
)
def __str__(self):
return self.error_message
Logging System
Comprehensive logging provides insights into system operations:
logging.basicConfig(
filename=LOG_FILE_PATH,
format="[ %(asctime)s ] %(lineno)d %(name)s - %(levelname)s - %(message)s",
level=logging.INFO,
)
Entity Configurations
Data classes define configurations and artifacts for each component:
@dataclass
class DataIngestionConfig:
raw_data_path: str = os.path.join('artifacts', 'raw.csv')
train_data_path: str = os.path.join('artifacts', 'train.csv')
test_data_path: str = os.path.join('artifacts', 'test.csv')
Testing Strategy
A comprehensive testing strategy includes:
- Unit Tests: Testing individual components in isolation
- Integration Tests: Testing interactions between components
- End-to-End Tests: Testing complete pipelines
Using the Template
- Setting Up the Project Run the project setup script to create the directory structure and template files:
python project_setup.py - Installing Dependencies
pip install -r requirements.txt - Implementing Components Fill in the implementation details for each component based on your specific use case.
- Running the Pipeline
from main import start_training, start_prediction # Train model training_results = start_training() # Make prediction data = {"feature1": 10, "feature2": 20, "feature3": "category_a"} prediction = start_prediction(data)
Best Practices
- Configuration Management: Store all configurable parameters in configuration files
- Artifact Management: Save intermediate artifacts for reproducibility and debugging
- Exception Handling: Use custom exceptions for clear error messages
- Logging: Implement comprehensive logging for monitoring and debugging
- Testing: Create tests for all components to ensure reliability
- Documentation: Document code thoroughly for maintainability
Conclusion
Building a modular machine learning project requires careful planning and structure, but the benefits far outweigh the initial investment. This architecture provides a solid foundation for developing ML systems that are maintainable, scalable, and production-ready.
By following the patterns outlined in this post, you can streamline your ML development workflow and focus on solving business problems rather than wrestling with code organization issues.
Whether you’re working on a small personal project or a large enterprise system, this modular approach will help you create robust machine learning applications that can confidently transition from experimentation to production.