
Introduction
The encoder-decoder architecture represents one of the most influential developments in deep learning, particularly for sequence-to-sequence tasks. This architecture has revolutionized machine translation, speech recognition, image captioning, and many other applications where input and output data have different structures or lengths.
In this blog post, we’ll explore:
- The fundamental concepts behind encoder-decoder architectures
- Detailed breakdown of encoder and decoder components
- Core mechanisms including attention
- Step-by-step implementations with PyTorch
- Architectural diagrams and visualizations
- Advanced variants and state-of-the-art applications
Table of Contents
- Fundamentals of Encoder-Decoder Architecture
- The Encoder: Deep Dive
- The Decoder: Deep Dive
- Attention Mechanisms
- Implementation: Neural Machine Translation
- Training and Inference
- Advanced Architectures
- Applications and Use Cases
- Best Practices and Optimization
- Conclusion
<a name=”fundamentals”></a>
1. Fundamentals of Encoder-Decoder Architecture
Basic Concept
At its core, the encoder-decoder architecture consists of two main components:
- Encoder: Processes the input sequence and compresses it into a context vector (or a set of vectors)
- Decoder: Takes the context vector and generates the output sequence
This design allows the model to map between sequences of different types or lengths – for example, a sentence in English to its translation in French, or an image to a descriptive caption.
The Information Flow
Input Sequence → Encoder → Context Vector(s) → Decoder → Output Sequence
Why Encoder-Decoder?
Traditional neural networks struggle with:
- Variable-length inputs and outputs
- Different dimensions between input and output spaces
- Preserving sequential relationships
The encoder-decoder architecture elegantly addresses these challenges by:
- Converting variable-length input into fixed-length representations
- Allowing different dimensionality in input and output
- Preserving sequence information through recurrent connections or attention
Main Variants
- RNN-based: Using LSTM or GRU cells for both encoder and decoder
- CNN-based: Using convolutional layers for encoding and sometimes decoding
- Transformer-based: Using self-attention mechanisms instead of recurrence
- Hybrid approaches: Combining different neural architectures
<a name=”encoder”></a>
2. The Encoder: Deep Dive
Purpose and Function
The encoder’s job is to process the input sequence and create a meaningful representation that captures its essential information. This representation should:
- Contain semantic information about the input
- Capture relationships between elements in the sequence
- Be in a form that the decoder can effectively use
Common Encoder Architectures
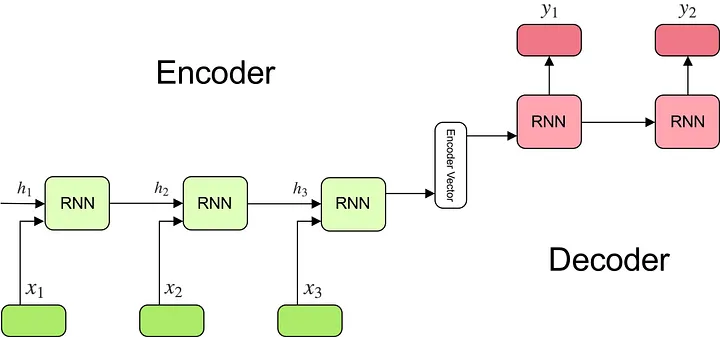
1. RNN-based Encoder
h₁ h₂ h₃ hₙ
↑ ↑ ↑ ↑
| | | |
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ RNN │───│ RNN │───│ RNN │···│ RNN │
└─────┘ └─────┘ └─────┘ └─────┘
↑ ↑ ↑ ↑
x₁ x₂ x₃ xₙ
In an RNN encoder:
- Input tokens (x₁, x₂, …, xₙ) are processed sequentially
- Each RNN cell updates its hidden state based on the current input and previous hidden state
- The final hidden state (sometimes all hidden states) serves as the context vector
2. Bidirectional RNN Encoder
→→→→ Forward RNN →→→→
h₁← h₂← h₃← ... hₙ←
↑ ↑ ↑ ↑
x₁ x₂ x₃ ... xₙ
↓ ↓ ↓ ↓
h₁→ h₂→ h₃→ ... hₙ→
←←←← Backward RNN ←←←←
Bidirectional encoders:
- Process the sequence in both forward and backward directions
- Capture context from both past and future tokens
- Concatenate or combine both directions’ hidden states
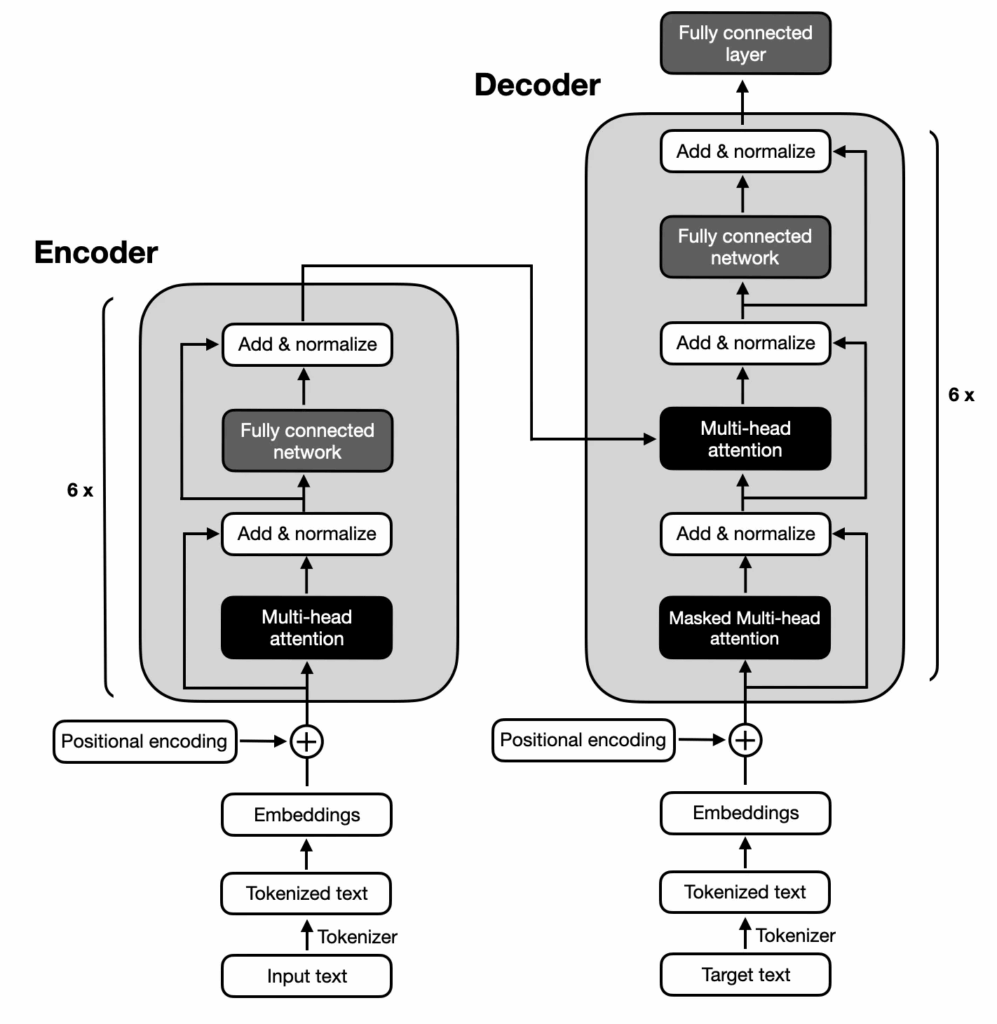
3. Transformer Encoder
Multi-Head Self-Attention
↑
|
Add & Normalize
↑
|
Feed-Forward Neural Network
↑
|
Add & Normalize
↑
|
Positional Encoding
↑
|
Input Embedding
Transformer encoders:
- Process the entire sequence in parallel
- Use self-attention to model relationships between all positions
- Apply position encoding to maintain sequence order
- Stack multiple layers for deeper representations
Implementation of a Basic RNN Encoder
import torch
import torch.nn as nn
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, embedding_size, num_layers=1, dropout=0.1):
"""
Arguments:
input_size: Size of vocabulary
hidden_size: Size of the hidden state
embedding_size: Size of the word embeddings
num_layers: Number of RNN layers
dropout: Dropout probability
"""
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# Word embedding layer
self.embedding = nn.Embedding(input_size, embedding_size)
# LSTM layer
self.lstm = nn.LSTM(
embedding_size,
hidden_size,
num_layers=num_layers,
bidirectional=True, # Using bidirectional LSTM
dropout=dropout if num_layers > 1 else 0,
batch_first=True
)
# Project bidirectional outputs to hidden_size
self.fc = nn.Linear(hidden_size * 2, hidden_size)
def forward(self, x, x_lengths):
"""
Arguments:
x: Input sequence tensor [batch_size, seq_len]
x_lengths: Length of each sequence in the batch
Returns:
outputs: All encoder hidden states [batch_size, seq_len, hidden_size]
hidden: Final encoder hidden state [num_layers*2, batch_size, hidden_size]
"""
batch_size = x.size(0)
# Create embedding
embedded = self.embedding(x) # [batch_size, seq_len, embedding_size]
# Pack padded sequence for efficient computation
packed = nn.utils.rnn.pack_padded_sequence(
embedded, x_lengths.cpu(), batch_first=True, enforce_sorted=False
)
# Forward through LSTM
outputs, (hidden, cell) = self.lstm(packed)
# Unpack outputs
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs, batch_first=True)
# Combine bidirectional outputs
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1) # [batch_size, 2*hidden_size]
hidden = torch.tanh(self.fc(hidden)) # [batch_size, hidden_size]
# Reshape for decoder
hidden = hidden.unsqueeze(0).repeat(self.num_layers, 1, 1) # [num_layers, batch_size, hidden_size]
return outputs, hidden
Implementation of a Transformer Encoder Layer
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
"""
Arguments:
d_model: Model dimension/embedding size
nhead: Number of attention heads
dim_feedforward: Dimension of feed-forward network
dropout: Dropout probability
"""
super(TransformerEncoderLayer, self).__init__()
# Multi-head self-attention
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Feed-forward network
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model)
)
# Normalization layers
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
"""
Arguments:
src: Source sequence [seq_len, batch_size, d_model]
src_mask: Mask to prevent attention to certain positions
src_key_padding_mask: Mask for padded positions
Returns:
output: Encoded output [seq_len, batch_size, d_model]
"""
# Self-attention block
attn_output, _ = self.self_attn(
src, src, src,
attn_mask=src_mask,
key_padding_mask=src_key_padding_mask
)
src = src + self.dropout1(attn_output)
src = self.norm1(src)
# Feed-forward block
ff_output = self.feed_forward(src)
src = src + self.dropout2(ff_output)
src = self.norm2(src)
return src
<a name=”decoder”></a>
3. The Decoder: Deep Dive
Purpose and Function
The decoder generates the output sequence based on:
- The context representation from the encoder
- Previously generated outputs
- Its own internal state
Its main functions are:
- Interpreting the encoder’s representation
- Maintaining context during generation
- Producing coherent output sequences
Common Decoder Architectures
1. RNN-based Decoder
┌───────┐ ┌───────┐ ┌───────┐
│ RNN │───>│ RNN │───>│ RNN │ ...
└───────┘ └───────┘ └───────┘
↑ ↑ ↑ ↑ ↑ ↑
│ │ │ │ │ │
┌──┘ │ ┌──┘ │ ┌──┘ │
│ │ │ │ │ │
y₀ ctx y₁ ctx y₂ ctx
In an RNN decoder:
- Initialized with the encoder’s final state
- Takes previous output token and context as input
- Generates probability distribution for the next token
2. Attention-based Decoder
Attention Weights
↗ ↑ ↖
↗ │ ↖
┌───────┐↗ ┌───────┐ ↖┌───────┐
│ RNN │───>│ RNN │───>│ RNN │ ...
└───────┘ └───────┘ └───────┘
↑ ↑ ↑ ↑ ↑ ↑
│ │ │ │ │ │
┌──┘ │ ┌──┘ │ ┌──┘ │
│ │ │ │ │ │
y₀ ctx₀ y₁ ctx₁ y₂ ctx₂
With attention:
- Each decoder step has access to all encoder states
- Attention weights determine which encoder states to focus on
- Context vector is dynamically computed at each step
3. Transformer Decoder
Multi-Head Self-Attention
↑
|
Add & Normalize
↑
|
Multi-Head Cross-Attention
↑
|
Add & Normalize
↑
|
Feed-Forward Neural Network
↑
|
Add & Normalize
↑
|
Output Embedding
↑
|
Shifted Right Input
Transformer decoders:
- Use masked self-attention to prevent looking at future positions
- Include cross-attention to encoder outputs
- Process previously generated tokens in parallel during training
Implementation of a Basic RNN Decoder
class DecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size, embedding_size, num_layers=1, dropout=0.1):
"""
Arguments:
output_size: Size of target vocabulary
hidden_size: Size of the hidden state
embedding_size: Size of the word embeddings
num_layers: Number of RNN layers
dropout: Dropout probability
"""
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
# Word embedding layer
self.embedding = nn.Embedding(output_size, embedding_size)
# LSTM layer
self.lstm = nn.LSTM(
embedding_size,
hidden_size,
num_layers=num_layers,
dropout=dropout if num_layers > 1 else 0,
batch_first=True
)
# Output projection
self.fc_out = nn.Linear(hidden_size, output_size)
# Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
"""
Arguments:
input: Input token indices [batch_size, 1]
hidden: Hidden state from encoder or previous step [num_layers, batch_size, hidden_size]
cell: Cell state [num_layers, batch_size, hidden_size]
Returns:
output: Next token probabilities [batch_size, output_size]
hidden: Updated hidden state
cell: Updated cell state
"""
# Embed input tokens
embedded = self.dropout(self.embedding(input)) # [batch_size, 1, embedding_size]
# Pass through LSTM
output, (hidden, cell) = self.lstm(embedded, (hidden, cell))
# output: [batch_size, 1, hidden_size]
# Project to vocabulary size
prediction = self.fc_out(output.squeeze(1)) # [batch_size, output_size]
return prediction, hidden, cell
Implementation of a Decoder with Attention
class AttentionDecoder(nn.Module):
def __init__(self, output_size, hidden_size, embedding_size, attention_size, num_layers=1, dropout=0.1):
"""
Arguments:
output_size: Size of target vocabulary
hidden_size: Size of the hidden state
embedding_size: Size of the word embeddings
attention_size: Size of attention layer
num_layers: Number of RNN layers
dropout: Dropout probability
"""
super(AttentionDecoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
# Word embedding layer
self.embedding = nn.Embedding(output_size, embedding_size)
# Attention mechanism
self.attention = nn.Linear(hidden_size * 2, attention_size)
self.attention_combine = nn.Linear(hidden_size + embedding_size, hidden_size)
# LSTM layer
self.lstm = nn.LSTM(
hidden_size,
hidden_size,
num_layers=num_layers,
dropout=dropout if num_layers > 1 else 0,
batch_first=True
)
# Output projection
self.fc_out = nn.Linear(hidden_size, output_size)
# Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell, encoder_outputs):
"""
Arguments:
input: Input token indices [batch_size, 1]
hidden: Hidden state [num_layers, batch_size, hidden_size]
cell: Cell state [num_layers, batch_size, hidden_size]
encoder_outputs: All encoder hidden states [batch_size, input_length, hidden_size]
"""
# Embed input tokens
embedded = self.dropout(self.embedding(input)) # [batch_size, 1, embedding_size]
# Calculate attention weights
h_top = hidden[-1].unsqueeze(1) # Get top layer's hidden state [batch_size, 1, hidden_size]
# Repeat for concatenation with encoder outputs
h_expanded = h_top.repeat(1, encoder_outputs.size(1), 1) # [batch_size, input_length, hidden_size]
# Concatenate
attn_input = torch.cat((encoder_outputs, h_expanded), dim=2) # [batch_size, input_length, hidden_size*2]
# Calculate attention scores
attn_scores = self.attention(attn_input) # [batch_size, input_length, attention_size]
attn_scores = torch.tanh(attn_scores)
attn_scores = torch.sum(attn_scores, dim=2) # [batch_size, input_length]
# Convert scores to weights with softmax
attn_weights = F.softmax(attn_scores, dim=1).unsqueeze(1) # [batch_size, 1, input_length]
# Apply attention weights to encoder outputs
context = torch.bmm(attn_weights, encoder_outputs) # [batch_size, 1, hidden_size]
# Combine context with input embedding
rnn_input = torch.cat((embedded, context), dim=2) # [batch_size, 1, embedding_size + hidden_size]
rnn_input = self.attention_combine(rnn_input) # [batch_size, 1, hidden_size]
rnn_input = F.relu(rnn_input)
# Pass through LSTM
output, (hidden, cell) = self.lstm(rnn_input, (hidden, cell))
# Project to vocabulary size
prediction = self.fc_out(output.squeeze(1)) # [batch_size, output_size]
return prediction, hidden, cell, attn_weights
Implementation of a Transformer Decoder Layer
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
"""
Arguments:
d_model: Model dimension/embedding size
nhead: Number of attention heads
dim_feedforward: Dimension of feed-forward network
dropout: Dropout probability
"""
super(TransformerDecoderLayer, self).__init__()
# Multi-head self-attention
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Multi-head cross-attention to encoder outputs
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Feed-forward network
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model)
)
# Normalization layers
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
# Dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None,
tgt_key_padding_mask=None, memory_key_padding_mask=None):
"""
Arguments:
tgt: Target sequence [tgt_len, batch_size, d_model]
memory: Memory from encoder [src_len, batch_size, d_model]
tgt_mask: Mask to prevent attention to future positions
memory_mask: Mask for encoder memory
tgt_key_padding_mask: Mask for padded positions in target
memory_key_padding_mask: Mask for padded positions in memory
Returns:
tgt: Decoded output [tgt_len, batch_size, d_model]
"""
# Self-attention block with mask to prevent attending to future positions
q = k = v = tgt
tgt2, _ = self.self_attn(
q, k, v,
attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask
)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# Cross-attention block between decoder queries and encoder keys/values
tgt2, _ = self.multihead_attn(
query=tgt,
key=memory,
value=memory,
attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask
)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
# Feed-forward block
tgt2 = self.feed_forward(tgt)
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
<a name=”attention”></a>
4. Attention Mechanisms
Why Attention?
The attention mechanism was developed to address a fundamental limitation of the basic encoder-decoder architecture:
- Problem: Fixed-size context vector becomes an information bottleneck, especially for long sequences
- Solution: Allow decoder to directly access all encoder hidden states, weighting them based on relevance
How Attention Works
- For each decoder step, calculate a set of attention scores between:
- Current decoder hidden state (query)
- Each encoder hidden state (keys)
- Convert scores to weights using softmax
- Weights sum to 1, acting as a probability distribution over encoder states
- Create context vector as weighted sum of encoder states
- Multiply each encoder state by its weight and sum
- Use context vector along with current decoder state to predict next output
Types of Attention
1. Bahdanau/Additive Attention
score(s_t, h_i) = v_a^T tanh(W_a[s_t; h_i])
- Concatenates decoder state and encoder state
- Passes through a feed-forward layer
- Projects to a scalar score
2. Luong/Multiplicative Attention
score(s_t, h_i) = s_t^T W_a h_i
- Uses dot product between transformed decoder and encoder states
- Computationally more efficient
3. Scaled Dot-Product Attention
Attention(Q, K, V) = softmax(QK^T / √d_k)V
- Used in Transformers
- Scales dot product to prevent small gradients with large dimensions
4. Multi-Head Attention
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O
where head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
- Projects queries, keys, and values h times
- Performs attention on each projection
- Concatenates results and projects again
Implementation of Basic Attention Mechanism
class Attention(nn.Module):
def __init__(self, hidden_size, method="dot"):
"""
Arguments:
hidden_size: Size of hidden states
method: Attention method ('dot', 'general', 'concat')
"""
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.method = method
if method == 'general':
self.attn = nn.Linear(hidden_size, hidden_size)
elif method == 'concat':
self.attn = nn.Linear(hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(1, hidden_size))
def forward(self, hidden, encoder_outputs):
"""
Arguments:
hidden: Current decoder hidden state [batch_size, hidden_size]
encoder_outputs: All encoder hidden states [batch_size, seq_len, hidden_size]
Returns:
attention_weights: Attention weights [batch_size, seq_len]
"""
batch_size = encoder_outputs.size(0)
seq_len = encoder_outputs.size(1)
# Create a score for each encoder output
if self.method == 'dot':
# Simple dot product between decoder hidden and encoder outputs
energy = torch.bmm(
hidden.unsqueeze(1), # [batch_size, 1, hidden_size]
encoder_outputs.transpose(1, 2) # [batch_size, hidden_size, seq_len]
) # [batch_size, 1, seq_len]
return F.softmax(energy.squeeze(1), dim=1)
elif self.method == 'general':
# Linear transformation then dot product
energy = torch.bmm(
hidden.unsqueeze(1), # [batch_size, 1, hidden_size]
self.attn(encoder_outputs).transpose(1, 2) # [batch_size, hidden_size, seq_len]
) # [batch_size, 1, seq_len]
return F.softmax(energy.squeeze(1), dim=1)
elif self.method == 'concat':
# Concatenation-based attention
hidden_expanded = hidden.unsqueeze(1).expand(-1, seq_len, -1) # [batch_size, seq_len, hidden_size]
concat = torch.cat((hidden_expanded, encoder_outputs), dim=2) # [batch_size, seq_len, 2*hidden_size]
energy = self.attn(concat) # [batch_size, seq_len, hidden_size]
energy = torch.tanh(energy)
energy = torch.bmm(
self.v.repeat(batch_size, 1, 1), # [batch_size, 1, hidden_size]
energy.transpose(1, 2) # [batch_size, hidden_size, seq_len]
) # [batch_size, 1, seq_len]
return F.softmax(energy.squeeze(1), dim=1)
Implementation of Scaled Dot-Product Attention
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Compute scaled dot-product attention.
Arguments:
query: Query tensors [batch_size, num_heads, query_len, depth]
key: Key tensors [batch_size, num_heads, key_len, depth]
value: Value tensors [batch_size, num_heads, value_len, depth]
mask: Optional mask [batch_size, num_heads, query_len, key_len]
Returns:
output: Attention output [batch_size, num_heads, query_len, depth]
attention_weights: Attention weights [batch_size, num_heads, query_len, key_len]
"""
# Calculate dot product of query and key
matmul_qk = torch.matmul(query, key.transpose(-2, -1)) # [batch_size, num_heads, query_len, key_len]
# Scale by square root of the depth
depth = query.size(-1)
matmul_qk = matmul_qk / math.sqrt(depth)
# Apply mask if provided
if mask is not None:
matmul_qk = matmul_qk.masked_fill(mask == 0, -1e9)
# Apply softmax to get attention weights
attention_weights = F.softmax(matmul_qk, dim=-1) # [batch_size, num_heads, query_len, key_len]
# Apply attention weights to values
output = torch.matmul(attention_weights, value) # [batch_size, num_heads, query_len, depth]
return output, attention_weights
<a name=”implementation”></a>
5. Implementation: Neural Machine Translation
Now, let’s implement a complete encoder-decoder model for machine translation. We’ll build a sequence-to-sequence model with attention for translating between languages.
Complete Seq2Seq Model with Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
class Encoder(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, num_layers, dropout):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, embedding_size)
self.dropout = nn.Dropout(dropout)
self.rnn = nn.GRU(
embedding_size,
hidden_size,
num_layers=num_layers,
bidirectional=True,
dropout=dropout if num_layers > 1 else 0,
batch_first=True
)
self.fc = nn.Linear(hidden_size * 2, hidden_size)
def forward(self, x, lengths):
# x: [batch_size, seq_len]
embedded = self.dropout(self.embedding(x)) # [batch_size, seq_len, embedding_size]
# Pack padded sequences
packed = nn.utils.rnn.pack_padded_sequence(
embedded, lengths.cpu(), batch_first=True, enforce_sorted=False
)
outputs, hidden = self.rnn(packed)
# Unpack outputs
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs, batch_first=True)
# outputs: [batch_size, seq_len, hidden_size*2]
# Combine bidirectional states
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1) # [batch_size, hidden_size*2]
hidden = self.fc(hidden) # [batch_size, hidden_size]
hidden = torch.tanh(hidden)
# Reshape for decoder initialization
hidden = hidden.unsqueeze(0).repeat(self.num_layers, 1, 1) # [num_layers, batch_size, hidden_size]
return outputs, hidden
class Attention(nn.Module